Добре дошли в част 2 от „Обзор на Zen 2“. В миналата част обсъдихме част от историята на CPU пазара през последните ~10 години. В тази на фокус ще бъде Zen архитектурата, подобренията в нея, някои сравнения с Intel и разбира се, анализ на тази промяна. В част 3 ще представя своите мисли за значението на Zen архитектурата извън AMD вакуума. В крайна сметка, нищо няма значение, ако не може да бъде измерено. А нищо не може да бъде измерено, без поне две точки, нали?
Съдържание
Zen архитектурата
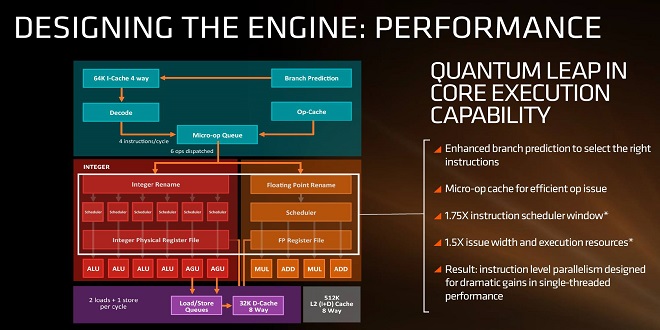
Преди да продължим с втората част от Обзор на Zen 2, нека се запознаем с целите на AMD при създаването на Zen архитектурата. Jim Keller – бащата на Zen, магьосникът, архитектурният гений. От първите официални слайдове се видя, че AMD има няколко основни цели за постигане с крайния продукт от първото поколение:
- 40% подобрен IPC
- по-висока енергийна ефикасност
- един общ дизайн на ядро за всичко (от мобилни устройства до сървъри), показвайки че компанията залага всичко на Zen.
Погледнете изображението – в ляво виждате проста блокова диаграма на Zen архитектурата, а в дясно – тълкуването й на маркетингов език. Започваме пояснения на диаграмата от горе надолу – скачайте във влака!
Новост: micro-op кеш
За разлика от Bulldozer (и други дизайни на AMD), Zen включва micro-op cache, което е памет, използвана за съхранение на често използвани микро-операции (а не на х86 инструкции). В случая този нов кеш буфер дава възможност и за съхранение на данни, подадени от branch predictor-а, тъй като и той е бил обновен (каквото и да значи това точно). Важно е да се отбележи, че Intel използват подобен тип кеш памет от няколко поколения насам. Не ме цитирайте, но мисля, че е още от Nehalem (~2008г.!)
Анализ:
Този тип кеш помага на процеса с намалена латентност при търсене на често използвани микро-операции. При липсата му тези операции се съхраняват в други нива на кеш паметта, като това забавя тази стъпка от изчислителния процес. Също така, липсата му води до завишена консумация на енергия – всяко местене на данни е енергийно скъпо. Т.е. този нов кеш е предпоставка за енергийна ефикасност и увеличаване на IPC.
Новост: декодери
Нова структура на декодерите, позволяваща до 4 операции/цикъл. На прост език това означава, че новата архитектура позволява 4 операции да бъдат наредени (в изчакване на изпълнение) за всеки цикъл на изпълнение (извинете повтарянето – технически термин е, все пак). Тази цифра е тясно свързана с новия микро-оп кеш.
Важно: Червената част от диаграмата, наречена Integer и оградена в бял правоъгълник, е разделена на две части: integer и floating point изчислителни части. Тъй като всяка част има свой собствен scheduler, броят на операциите в изчакване се покачва до 6 (4+1+1), ако има по една инструкция за всеки изчислителен блок (integer + floating point).
Анализ:
Взимайки предвид новия микро-оп кеш и структурата на декодерите, дефакто получаваме 6-те операции, за които говорехме, защото самият микро-оп кеш служи като магистрала, водеща към изчислителните блокове. Краткото разстояние (търсене в микро-оп, вместо в L2, например) и кръстовището означават облекчен трафик дори при по-висок брой коли (двойните scheduler-и).
Само по себе си това е предпоставка за огромно подобрение откъм IPC. Между другото, Intel са обединили INT/FP изчисленията си в един блок от поколения насам, но въпреки това запазват своето IPC. Ще коментирам защо и как малко по-нататък.
Анализ – INT блок
От диаграмата се вижда, че INT блока на ядрото работи по предаването на маркерите към ALU/AGU операции. AGU (още познат като ACU) облекчава цялостната работа на процесора, като се занимава специфично с операции, изискващи достъпа до основната памет. Отделяйки тези операции от цялостната работа на процесора, даваме възможност за изпълнението на тези инструкции паралелно с други, което води до повишаване на производителността.
Т.е. виждаме още една предпоставка за по-високо IPC. ALU, от друга страна, има малко по-комплексна роля, което налага и свръх-опростяване на тази част от анализа. Представете си входно-изходна точка, която може да съдържа информация за последно изпълнената или следващата операция. ALU, в този смисъл, извършват INT операциите с добре познатия на всички ни двоичен код (1 и 0).
Тук е моментът, в които излизаме от червеното поле в диаграмата и се впускаме към лилавото. След като инструкциите са били подредени и изчисленията обработени, стигаме до т.нар. load/store units (LSU) – и ролята им е точно такава. Съхранение или пропускане на 16-байтови пакети. AMD показват, че са възможни 2 х 16 байта пропускания и 1 х 16 байта съхранение за всеки цикъл на работа. Имайте предвид, че тези пропускания/съхранения са свързани с комуникация с кеш паметите, така че скоростната комуникация е ключова за евентуални забавяния в целия процес.
Анализ – FP блок
Тук гледаме оранжевата част от диаграмата (дясната половина). Виждаме х2 броя MUL (multiply – умножение) и ADD (събиране) изчислителни части. Ако някой някога се е чудел какво изобщо представлява FMAC операцията, сега е моментът да го види нагледно. FMAC (fused multiply–accumulate) операцията включва в себе си събиране и умножение. Тъй като имаме х2 броя от всяка изчислителна част, можем да извършваме две слети FMAC операции или една 256-битова AVX.
Изчислителен блок – цялостен коментар
Този начин на комбиниране на двата изчислителни блока показва и какъв е плана на AMD – едно по-широко ядро. Широките ядра разчитат на висок паралелизъм в инструкциите, следователно ще се представят по-добре в товари, използващи няколко ядра/нишки едновременно. Последната част идва като естествен извод, защото всяко ядро/нишка е всъщност единица, изпълняваща низ от операции.
При кратки, но многобройни операции, ще имате по-висока производителност с по-широкото ядро, но само ако те могат да бъда изпълнявани паралелно. Също така е много важно да отбележим, че с подходящия (паралелен) товар, AMD са създали решение, което може да компенсира по-ниското IPC, характерно за по-късите ядра, чрез SMT и повишен брой на ядрата. Нещо, което очевидно те правят и е основният аргумент зад мнението, че AMD променят пазара.
Иска ми се да отбележа, че ядрата на Intel са по-дълги и разчитат на друг интерфейс за комуникация помежду си. Дългите ядра имат естествено по-високо IPC – ако цикълът е по-дълъг, е нормално да имате повече инструкции в него. Bulldozer се провали точно защото стигна до момент, в който прекалено дългото ядро има елементи в покой, когато товарът не е достатъчно дълъг или не използва всички елементи на архитектурата.
Кеш памети:
Последната огромна промяна в Zen архитектурата е свързана с организацията на кеш паметта. Тук ще стане малко сложно, тъй като ще правим сравнения както с предишните дизайни на AMD (включително Zen), така и със Skylake, но без тях нямаше да можем да направим истински обзор на Zen 2.
- Отделна low-level кеш памет (L1) за всяко ядро: в Bulldozer, две ядра споделяха обща L1 кеш памет. Макар внедряването на индивидуална кеш памет да е важно, със Zen виждаме и увеличаване в обема. Чрез тези две промени се очаква повишаване ефикасността на кеша за инструкции, което е предпоставка за повишаване на общото IPC на цялото ядро.
- Виждаме същата логика и в повишения обем на L2 кеш: 512 килобайта/ядро с 8-странна асоциативност. Skylake разполага с половината обем и половината асоциативност, но компенсира с обща L3 (LLC – last level cache) кеш памет.
- Говорейки за L3 – Skylake разполага с 2MB/ядро и 8-странна асоциативност, докато първото поколение Zen интегрира цялостно различна логика за интеграцията на кеш памет. Това се случва благодарение на новостите в създаването на пакета [т.нар. CCX (core complex)]. Имплементацията на кеш памет на такова високо ниво в Zen означава, че ядрата във всеки комплекс споделят обща кеш памет, т.нар. victim cache.
L3 имплементацията е пример за цялостната „широка” философия на Zen. Имайте предвид, че тази асоциативност е отговорна и за фрагментацията на отделните сетове инструкции. В зависимост от коя точка започвате, „широкото” ядро няма нужда от дълбок кеш. Казано наобратно – плиткият широко-асоциативен кеш налага нуждата от по-широко ядро. Не мога да кажа как точно е било взето решение по време на процеса на създаване, но логиката се свежда до този избор.
Друг начин да разгледаме L3 в Zen е като кеш „кошчето” на всеки CCX.
С пълна асоциативност L3 дава подобрено разпределение на инструкциите и намалява cache misses, но от друга страна лишава процесора от унифициран кеш на високо ниво (какъвто Intel имат – LLC). Това означава, че докато определен софтуер използва ядра от един CCX, общата кеш памет работи изключително успешно. Но AMD създават този дизайн с идеята един процесор да разполага с няколко CCX пакета, събрани в общ CCD чиплет. Комуникацията между отделните CCX добавя известна латентност, а липсата на унифициран кеш на високо ниво (какъвто Intel имат) допълнително ограничава процесора.
Контрасти с Intel
Общата кеш памет за всеки CCX дава възможност за ускорени операции, при които количеството е достатъчно и се изпълняват в рамките на един CCX. При изпълнение на операции извън ядрата от този CCX, имате добавена латентност. Т.е. тази операция ще работи изключително добре при AMD процесори, стига размера на L3 от този CCX да е достатъчен и операцията да използва локалната L3 памет, т.е. ядрата от един CCX.
Същия софтуер ще работи тотално различно при Intel. Всяко ядро разполага с унифицирания L3 кеш, което контрастира с подхода на AMD. Докато процесора на AMD ще има предимство при натоварване на индивидуална група от ядра, Intel ще има предимство при използването на всички ядра. Средната латентност при Intel е по-висока в сравнение с „локалната“ във всеки индивидуален CCX. За сметка на това, при „прескачане“ между групи ядра получавате по-висока латентност. Последното прави нещата интересни, защото сравнението между двата хипотетични процесора зависи от начина на изпълнение на софтуера.
Disclaimers
Не твърдя, че съм експерт по темата. По-скоро съм ентусиаст, който обича да чете. В този смисъл, ако откриете грешки, ви моля да ми ги посочите. В крайна сметка целта е да имаме събрана информация на едно място. Моля също така да се има предвид, че свръхопростяването на някои технически детайли е възможно да доведе до противоречия. В този ред на мисли не е излишно да се припомни, че това не е научен труд. Не всички в демографията ни са компютърни специалисти или още повече – разработчици на процесорни архитектури. Това е предпоставка за допълнително опростяване, а то от своя страна – за допълнителни противоречия.
Все пак това е края на коментарите за Zen архитектурата и също така – края на част 2.
Коментирайте чрез Facebook




